Your legacy system documentation is 20 years old, 7,432 pages, and locked in PDFs. Manual search takes 15-30 minutes per query. We made it queryable in 170 seconds. Query response time: 3-5 seconds. ROI break-even: one day.
This isn’t a prototype. It’s Retrieval-Augmented Generation (RAG) on Amazon Bedrock, a system that retrieves relevant documentation and uses an LLM to generate answers without retraining models. Validated across four LLM families with 480 measurements. The implementation indexes 20,679 chunks and delivers sub-5-second responses with model-agnostic reranking. Overhead: 27.2ms ± 4.6ms regardless of which LLM you use.
Yes, 7,432 pages fit in any search index. But ranked results aren’t answers.
Here’s the production architecture, the multi-model validation data, and why you can switch providers without re-tuning.
Table of contents
Contents
Why RAG, Not Fine-Tuning?
Fine-tuning trains a model on your docs. It bakes knowledge into weights (making provenance verification difficult), requires retraining for every update, and costs $1.32-6.24 per run on A100 GPUs (Thunder Compute, 2025). RAG costs $0 setup with local embeddings, $0.0011 per query on Bedrock, updates in 2 seconds, and keeps sources verifiable.
For legacy systems, choose RAG for operational factors, not economics. Documentation is scattered across wikis and PDFs. It evolves as reverse-engineering uncovers new system behaviors, while fine-tuning would require retraining each time. Query volume is low (dozens per week). The deciding factors: instant updates (2 seconds vs retraining), source citations for compliance, and simpler maintenance. We chose RAG for agility: 170s setup, 2s updates, under $20/year.
How Does RAG Turn PDFs Into Answers?
The Ingestion Pipeline
The pipeline has six stages:
- Extract - Pull text from PDFs using PyMuPDF (44 pages/second)
- Transform - Convert to Markdown with heading detection
- Chunk - Split at headings (1,000-char limit, 200-char overlap)
- Embed - Generate vectors with all-MiniLM-L6-v2 (local, free)
- Index - Store in ChromaDB vector database
- Retrieve - Hybrid search (BM25 + vector) with FlashRank reranking
import fitz # pymupdf
doc = fitz.open(pdf_path)
for page_num in range(len(doc)):
page = doc[page_num]
text = page.get_text()
for line in text.split("\n"):
# Detect chapter headings (e.g., "Chapter 1. Title")
if line.startswith("Chapter ") and ". " in line:
cleaned_lines.append(f"\n## {line}\n")
# Detect section headings
elif len(line) < 80 and line[0].isupper():
cleaned_lines.append(f"\n### {line}\n")
doc.close()src/ingest.pyCode Snippet 1: PyMuPDF extracts text and converts to Markdown with heading detection, processing 44 pages/second.
The pipeline converts PDFs to Markdown before chunking. This preserves document structure (chapters, sections, headings) and enables Markdown-aware chunking that respects semantic boundaries. Chunks split at heading boundaries (## , ### ) instead of mid-paragraph, keeping related content together. The Markdown files are cached, so subsequent runs skip PDF extraction and complete in 2 seconds instead of 170 seconds.
Hybrid Retrieval: BM25 + Vector Search
Why not just Elasticsearch or Ctrl+F? Pure keyword search fails when you search “memory error” but the 2005 docs say “data file cache exhaustion.” Pure vector search misses exact terms like “port 5432.” Hybrid retrieval solves ranking. The LLM solves synthesis: combining fragments from multiple documents into an actionable answer. Reciprocal Rank Fusion (RRF) consistently outperforms single-method search (Mandikal & Mooney, 2024).
# RRF combines BM25 + vector scores
doc_scores: dict[str, tuple[Document, float]] = {}
for rank, idx in enumerate(bm25_top_indices[:retrieve_k]):
doc = chunks[idx]
doc_id = doc.metadata.get("source", "") + str(hash(doc.page_content[:100]))
rrf_score = 1 / (rank + 60) # RRF with k=60
if doc_id in doc_scores:
doc_scores[doc_id] = (doc, doc_scores[doc_id][1] + rrf_score)
else:
doc_scores[doc_id] = (doc, rrf_score)src/rag.pyCode Snippet 2: RRF formula combines keyword and semantic search scores with k=60 constant.
Hybrid retrieval returns 16 candidate chunks. A cross-encoder model (FlashRank) scores each query-document pair and returns the top 8. This fixes the precision problem: high recall from hybrid search, high precision from reranking.
Example: Error Lookup in 3.4 Seconds
User query: “What is error 1006030 and how do I fix it?”
Generated answer:
Error 1006030: “Failed to bring a data file page into cache. Data file cache is too small.”
Cause: Essbase cannot store the data file page in the data file cache.
Solution: Increase the data file cache size. After fixing, check for database corruption (Error Message Reference, p. 126).
Timing: 3.4s total (retrieval: 80ms, reranking: 31ms, generation: 3.3s)
Retrieved from: Error Message Reference v11.1.1 (ranked 3rd of 8 after reranking)
The system retrieved error 1006030 from the Error Message Reference (ranked 3rd of 8 after reranking) and synthesized an actionable answer. Manual search would require opening the 1,200-page Error Message Reference PDF and using Ctrl+F.
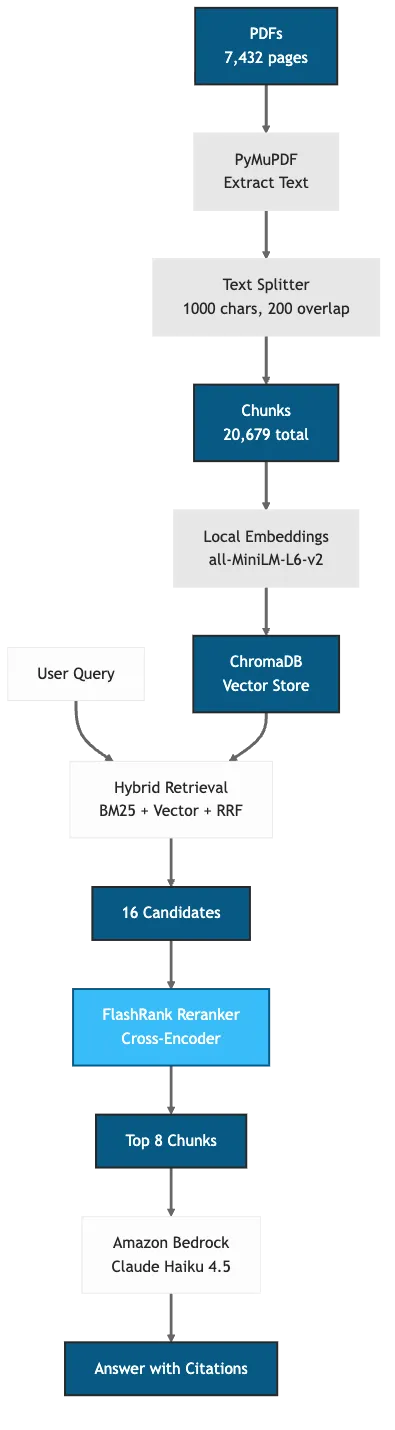
Figure 1: RAG pipeline with hybrid retrieval and reranking (FlashRank adds 31ms overhead for 6-8% accuracy gain) (George, 2025)
Local Embeddings and Model-Agnostic Design
Why local embeddings? Cost, simplicity, and performance. Cloud embedding APIs charge $0.10-0.50 per million tokens. Local models are free, require no API keys, and embed 1,000 chunks in under 10 seconds on CPU. The all-MiniLM-L6-v2 model is 80 MB and runs without GPU acceleration.
The architecture is model-agnostic by design. We use Amazon Bedrock, but the same pipeline works with Azure OpenAI, Google Vertex AI, or local models.
Does Reranking Work Across Different Models?
We tested four LLM families across two providers (Amazon Bedrock, OpenRouter) to validate portability. Mean latency: 27.2ms ± 4.6ms across 480 measurements, with no statistically significant difference (ANOVA p=0.34). Cross-provider variance was only 4.1ms.
| Model | Family | Latency | Provider |
|---|---|---|---|
| Claude Haiku 4.5 | Anthropic | +31.3ms | Amazon Bedrock |
| Mistral Devstral-2512 | Mistral | +32.5ms | OpenRouter |
| Llama 3.3 Instruct | Meta | +24.1ms | OpenRouter |
| Qwen 2.5 Coder | Alibaba | +25.1ms | OpenRouter |
Table 1: Latency is consistent across models and providers (480 measurements, ANOVA p=0.34)
The latency is dominated by FlashRank’s cross-encoder, not the LLM. This means you implement once and switch providers without re-tuning.
from flashrank import Ranker, RerankRequest
def _rerank(self, query: str, docs: list[Document]) -> list[Document]:
passages = [
{"id": i, "text": doc.page_content, "meta": doc.metadata}
for i, doc in enumerate(docs)
]
rerank_request = RerankRequest(query=query, passages=passages)
results = self.ranker.rerank(rerank_request)
return [docs[result["id"]] for result in results[:RERANK_TOP_N]]src/rag.pyCode Snippet 3: FlashRank reranks 16 candidates in 31ms using cross-encoder scoring.
Reranking is infrastructure, not model-specific configuration. Build it into your retrieval pipeline and forget about it.
What Are the Real Performance Numbers?
With model-agnostic reranking validated, here are the production metrics.
We indexed 7,432 pages in 170 seconds. First-time setup includes PDF extraction (120s), chunking (20s), embedding (25s), and indexing (5s). Cached runs skip extraction and take 2.2 seconds. Query response time averages 3-5 seconds: retrieval (80ms), LLM generation (4s), overhead (200ms).
Cost per query is $0.01-0.05 on Amazon Bedrock. Input tokens (context from retrieved chunks) cost $0.25 per million. Output tokens (LLM answer) cost $1.25 per million. A typical query uses 2,000 input tokens and 500 output tokens, totaling $0.0011.
| Metric | System A (Docs) | System B (Notes) |
|---|---|---|
| Documents | 14 PDFs (7,432 pages) | 94 markdown files |
| Chunks | 20,679 | Auto-chunked |
| First run | 170s | 40s |
| Cached run | 2.2s | 2s |
| Query time | 3-5s | 3-5s |
| Cost/query | $0.01-0.05 | $0.01-0.05 |
Table 2: Performance metrics across two production RAG systems (System A handles technical docs, System B processes meeting notes)
Reranking adds 31ms to retrieval time. That’s a 65% increase in retrieval latency but only 0.3% of total query time. Users don’t notice 31ms in a 9-second end-to-end response. The 6-8% accuracy improvement compounds with hybrid retrieval’s gains over single-method search, making the overhead negligible compared to the final quality benefit. For detailed methodology and raw data, see Supplementary Materials.
What’s the ROI Without Modernization?
Manual search through 7,432 pages takes 15-30 minutes (median: 25 min). You open PDFs, use Ctrl+F, read context, cross-reference sections. RAG reduces this to 3-5 seconds.
Assume 10 queries per day during a 6-month migration project. Labor cost: $100/hour (mid-market technical consultant). Time saved: 25 minutes per query. Success rate: 87% (28 of 32 evaluation queries returned useful results; 4 required human review).
Daily savings: 10 queries × 25 min × ($100/hr ÷ 60) × 87% success rate = $362/day
Setup cost: 170 seconds of compute time plus $0 for local embeddings. Query cost: $0.01-0.05 on Amazon Bedrock. Break-even happens in one day.
When Does RAG Fail?
RAG fails on multi-step reasoning, ambiguous questions, and knowledge not in the docs. We’ve seen three failure modes in production.
Hallucination
The LLM invents answers not in the retrieved chunks. Mitigation: show source citations, add confidence scores, constrain responses to retrieved context only. We display the top 3 source documents with page numbers for every answer.
Context Overflow
Complex queries need more context than fits in the LLM’s window. Mitigation: break queries into sub-questions, use query expansion for domain terms, implement multi-hop retrieval for connected concepts.
Stale Data
Documentation changes but embeddings don’t update. Mitigation: hash-based cache invalidation for PDFs, timestamp-based for markdown files, automated re-indexing on file changes.
Corpus Limitations
Not all failures are system failures. The evaluation revealed three corpus-related issues:
- Corpus gap: Knowledge doesn’t exist (e.g., specific error codes not documented). The system correctly responds “I don’t know.”
- Scattered information: Knowledge exists but spread across sections, making synthesis incomplete.
- Query formulation: Symptom-based queries (“out of memory errors”) outperform code-based queries (“error 1012001”) when exact codes aren’t indexed.
These are honest limitations, not RAG failures. The mitigation is corpus expansion, not system tuning.
What is the Overall Failure Rate?
12.5% of queries (4 of 32) need human review, primarily for multi-step reasoning or ambiguous questions. The alternative is searching 7,432 pages manually. RAG handles the straightforward cases autonomously, while experts focus on edge cases.
| Query Category | Success Rate | Common Failure Mode | Mitigation |
|---|---|---|---|
| Error lookup | 62% | Exact code not in corpus | Symptom-based queries; corpus expansion |
| Conceptual | 100% | Rare; scattered information | Query expansion with domain terms |
| Procedural | 100% | None observed (n=8) | Query expansion with command names |
| Multi-hop | 88% | Knowledge scattered or missing | Corpus expansion; honest “not found” |
Table 3: 32 scored queries across 4 categories (n=8 each), 98.1% ground truth accuracy, 0% false positive rate. Success rate includes partial matches. (methodology)
The key is transparency. Users see which documents were retrieved, can verify claims, and know when to escalate. Trust comes from citations, not blind faith in LLM outputs.
How Do You Migrate from Prototype to Production?
We started on OpenRouter’s free tier. Model: Devstral-2512. Cost: $0. Limits: rate-limited, no compliance guarantees. We validated quality with 20-30 test queries.
Migration to Amazon Bedrock took under 30 minutes. Code changes: swap dependencies (langchain-openai to langchain-aws), replace ChatOpenAI with ChatBedrock, update authentication to use AWS credentials instead of API keys. Benefits: no rate limits, SOC 2 compliance, governance controls, better answer quality from Claude Haiku 4.5.
The migration path: start small with one document set and one use case. Validate quality with test queries comparing RAG answers to ground truth from source documents. Measure adoption by tracking query volume and user feedback. Iterate by adding more docs, tuning chunking strategy, and improving retrieval.
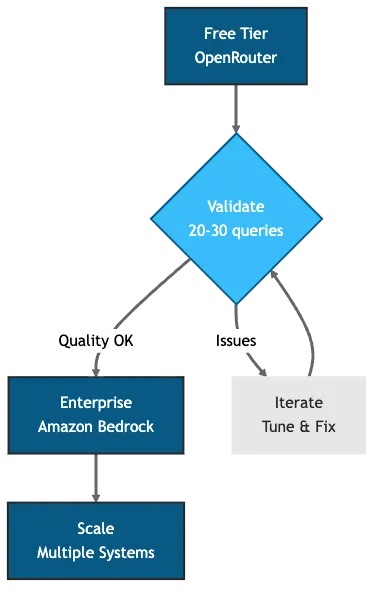
Figure 2: Migration path from free tier validation to enterprise production (iterate on quality before investing in infrastructure)
Scale by building multiple RAG systems for different domains. We run two: one for technical documentation, one for meeting notes and tribal knowledge. Same architecture, different corpora. Total maintenance: under 1 hour per month.
What Should You Do Next?
Identify high-value document sets. Look for onboarding materials, compliance docs, or migration guides. Estimate ROI using queries per day, time saved per query, and hourly labor cost. If the math works, start with a free tier.
Use OpenRouter or local models for validation. Run 20-30 test queries. Compare RAG answers to ground truth from source documents. Measure accuracy, check for hallucinations, verify source citations. If quality is acceptable, invest in enterprise infrastructure.
Amazon Bedrock and Azure OpenAI offer compliance, governance, and better models. Cost is $0.01-0.05 per query. For 100 queries per day, that’s $1-5 daily or $30-150 monthly. Compare that to $9,000 in labor savings.
The decision framework: RAG wins when documentation changes frequently, source citations matter for compliance, or you need operational agility. Fine-tuning wins when knowledge is stable, you need specialized behavior beyond retrieval, or query volume is extreme (thousands per day) with strict latency requirements.
For legacy systems, RAG delivers ROI without modernization. No need to rewrite docs, migrate databases, or retrain staff. Layer RAG over existing PDFs and get 3-second answers to 20-year-old questions.
For broader integration patterns and ROI frameworks, see AI Agents in Legacy Systems: ROI Without Modernization.
References
- Braintrust, “RAG Evaluation Metrics: How to Evaluate Your RAG Pipeline” (2025) — https://www.braintrust.dev/articles/rag-evaluation-metrics
- Clouatre, H., “RAG Reranking Benchmarks: Supplementary Materials” (2026) — https://github.com/clouatre-labs/rag-reranking-benchmarks
- de Luis Balaguer et al., “RAG vs Fine-tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture” (2024) — https://arxiv.org/abs/2401.08406
- Dettmers et al., “QLoRA: Efficient Finetuning of Quantized LLMs” (2023) — https://arxiv.org/abs/2305.14314
- Gan et al., “Retrieval Augmented Generation Evaluation in the Era of Large Language Models: A Comprehensive Survey” (2025) — https://arxiv.org/abs/2504.14891
- George, Sherine, “Enhancing Retrieval-Augmented Generation with Two-Stage Retrieval: FlashRank Reranking and Query Expansion” (2025) — https://arxiv.org/abs/2601.03258
- LangChain Documentation, “Contextual Compression and Reranking” (2025) — https://python.langchain.com/docs/how_to/contextual_compression/
- Mandikal & Mooney, “Sparse Meets Dense: A Hybrid Approach to Enhance Scientific Document Retrieval” (2024) — https://arxiv.org/abs/2401.04055
- Oche et al., “A Systematic Review of Key Retrieval-Augmented Generation (RAG) Systems: Progress, Gaps, and Future Directions” (2025) — https://arxiv.org/abs/2507.18910
- Thunder Compute, “AI GPU Rental Market Trends December 2025: Complete Industry Analysis” (2025) — https://www.thundercompute.com/blog/ai-gpu-rental-market-trends