AI tooling budgets hit record highs. We ran 90 file-prediction trials to measure what an AI agent gets wrong before it touches production. The model predicted 1.7 files beyond the actual change set on average, even on a well-structured codebase. Meanwhile, operational toil is climbing for the first time in years. SRE is not ceremony. It is the empirical gate between velocity and blast radius.
Table of contents
Contents
Why Is AI Widening the Dev/Ops Gap?
Toil is the repetitive, manual operational work that scales with system load rather than adding lasting value. Catchpoint’s annual SRE reports tracked toil rising from 25% to 34% between 2024 and 2026, the first sustained increase since the survey began in 2020. DORA’s 2025 report independently confirmed that AI tooling has not reduced operational toil. Over the same period, 92% of developers report that AI tools increase the blast radius of bad code needing to be debugged (DevOps.com, 2025). AI-generated code flows through pipelines designed for human-paced change, and the human-in-the-loop guardrails have not kept up. Defensive pipeline architectures can close part of this gap, but they address the pipeline, not the production governance layer.
Three root causes keep surfacing in post-mortems:
- AI babysitting: someone has to review generated runbooks and roll back missed-context remediations
- Configuration drift: accelerating faster than humans can audit it
- Validation overhead: compounding because every AI output needs a trust-but-verify pass before production
More frequent deploys, multiplied by more autonomous agents, against review capacity that has not scaled to match. METR found experienced developers took 19% longer with AI tools despite perceiving a 20% speedup (Becker et al., 2025). DORA 2025 confirmed faster deployment frequency but flat organizational delivery.
The Perception Gap: Dashboards vs. Practitioner Reality
The perception gap makes this harder to fix. Directors reviewing dashboards see ticket counts drop and declare victory. Practitioners on the ground feel increased friction because toil shifted from “boring but predictable” to “novel and unpredictable.” Both views are correct, which is exactly why the problem persists.
| Dimension | AI Accelerated | Human Judgment Required |
|---|---|---|
| Code generation | Higher code volume | Architectural review |
| Test creation | Unit test scaffolding | Integration test design |
| Deploy frequency | Higher deploy cadence | Change risk assessment |
| Incident detection | Faster alert correlation | Root cause judgment |
| Compliance | Automated scanning | Regulatory interpretation |
Table 1: AI accelerates delivery tasks (left column), but human judgment gaps (right column) are where incidents originate.
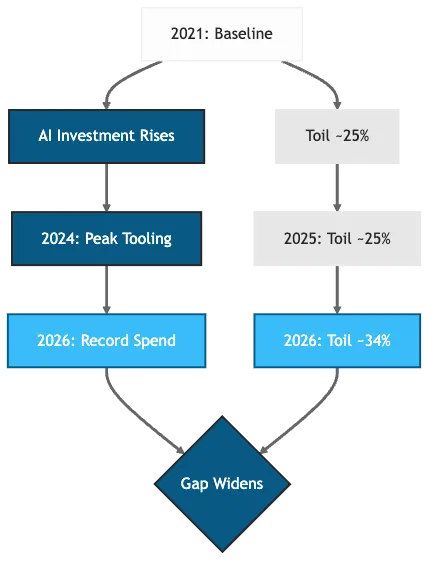
Figure 1: AI investment and measured toil both climbing, 2021-2026.
How Did We Measure AI’s Scope Creep?
Inspired by the SWE-bench methodology (Jimenez et al., 2024), we designed a file-prediction study: given a GitHub issue description and the repository file tree at a PR’s base commit, can Claude Sonnet 4.6 predict which files a human engineer modified? We targeted tobymao/sqlglot, an MIT-licensed SQL transpiler with 9k+ stars and a predictable dialect-file structure. We curated 30 merged PRs, stratified by complexity (10 simple, 10 medium, 10 complex), and ran 3 predictions per PR for 90 total trials. A single Bedrock API call per prediction: no agent loop, no tools, no retrieval. For detailed methodology and raw data, see Supplementary Materials.
Each prediction was scored against the human’s actual change set using file-level precision, recall, F1, and Jaccard similarity (set overlap: intersection over union). Scope creep, what we term scope hallucination, counts how many extra files the model predicted beyond the human’s set. These are changes the model hallucinated that do not exist in the human’s actual changeset.
| Tier | Precision / Recall | F1 | Scope Creep |
|---|---|---|---|
| Simple (1-2 files) | 0.645 / 0.850 | 0.708 | 1.3 files |
| Medium (3-5 files) | 0.540 / 0.585 | 0.552 | 2.2 files |
| Complex (6-15 files) | 0.769 / 0.673 | 0.712 | 1.6 files |
Table 2: Results by complexity tier, 30 PRs x 3 runs = 90 total predictions. F1 is the harmonic mean of precision and recall. Full methodology, metrics, and per-tier results.
Why Medium-Tier PRs Underperformed
The non-monotonic curve is the headline finding: Jaccard similarity was 0.60 (simple), 0.41 (medium), and 0.58 (complex). Medium-tier PRs underperformed both simple and complex tiers. The model struggles most with moderate-scope changes, not the largest ones. Medium PRs occupy the worst of both tiers. Too many candidate files to guess by elimination (as with simple PRs), but not enough structural regularity for the model to infer the set from sqlglot’s dialect-file conventions (as with complex PRs). Complex PRs had the highest precision, likely because sqlglot’s rigid directory structure (dialect file plus corresponding test file) makes multi-file change sets predictable from the dialect name alone. 12 of 30 PRs failed (Jaccard < 0.5), spread across all tiers; no tier is immune. In a shadow-mode deployment, where the agent proposes changes but a human applies them, every over-predicted file is a false positive the reviewer filters out before the change reaches production.
What Does SRE Mean in a Regulated Enterprise?
SRE is not DevOps with a different name. The distinction is structural. In regulated financial services, production reliability carries regulatory weight: OSFI’s B-13 guideline mandates technology risk management with board-level accountability, and the EU’s DORA regulation sets equivalent requirements for operational resilience across European financial services (European Parliament and Council, 2022). The compliance surface extends beyond infrastructure to AI-driven supply chain risks that traditional dependency scanning does not catch.
Error Budgets as Compliance Evidence
SRE answers this with a reliability contract. Error budgets define how much unreliability a service can tolerate before feature work stops. SLOs (service level objectives) make reliability measurable rather than aspirational. Blameless postmortems treat incidents as system failures, not personnel failures. Google codified this framework in 2016 and enterprises have since adapted it, but in regulated environments the stakes include regulatory censure, not just customer churn.
Platform Engineering provides capability: the tools, the internal developer platform, the golden paths. Where model governance and operational resilience frameworks intersect with SRE practices, the regulatory surface extends from infrastructure to inference. SRE provides accountability: the error budgets, the incident response, the production governance. The question is whether that accountability holds when the agent making changes is not human.
How Does SRE Act as AI’s Production Conscience?
Deploying an AI agent is not a monitoring problem. It is a reliability problem. Monitoring tells you something broke. A reliability framework tells you how much breakage you can tolerate, who caused it, and whether to keep going.
Decision Provenance and Error Budget Separation
Decision provenance, the AI observability requirement that every agent action links to its inputs, reasoning, and authorization chain, goes beyond logging what an agent did. You need to trace why it made a choice, what context it consumed, and which prior decisions influenced the outcome. Without this, debugging an autonomous system is archaeology, not engineering. Under OSFI B-13 and DORA, an agent action without decision provenance is not just a debugging gap; it is a compliance liability.
Separate error budgets for AI-generated changes keep machine-authored deployments from hiding behind human baselines. If an AI agent burns through its error budget, its write permissions get revoked automatically, not the entire team’s. Our results showed 0.769 precision even on the best-performing tier, meaning roughly 1 in 4 predicted files was wrong. That error rate needs its own budget.
groups:
- name: sli.deploys
rules:
- record: sli:deploy_success:ratio1h
expr: |
sum(rate(deploy_success_total{author_type="ai"}[1h]))
/ sum(rate(deploys_total{author_type="ai"}[1h]))
labels:
author_type: ai
slo_target: "0.995" # Stricter than human baseline of 0.990
- record: sli:deploy_success:ratio1h
expr: |
sum(rate(deploy_success_total{author_type="human"}[1h]))
/ sum(rate(deploys_total{author_type="human"}[1h]))
labels:
author_type: human
slo_target: "0.990"
- alert: AIChangeErrorBudgetBurnRate
expr: |
(1 - sli:deploy_success:ratio1h{author_type="ai"})
/ (1 - 0.995) > 14.4
for: 5m
labels:
severity: critical
team: sresli-and-burn-rate.yamlCode Snippet 1: Prometheus recording rules and burn-rate alert for AI-authored deployments. Separate SLIs per author type; 14.4x burn-rate threshold from the Google SRE Workbook.
Production teams consistently trade agent capability for reliability, preferring narrower but predictable automation over broad but brittle autonomy (Pan et al., 2026). Separate error budgets formalize that trade-off.
Blast Radius Containment and the Trust Ladder
Blast radius containment means progressive rollout gates. No agent ships to 100% on day one. The trust ladder, a graduated set of AI guardrails where each rung grants broader blast radius only after the agent demonstrates reliability at the current level, makes this concrete: start with read-only agents, graduate to shadow mode for 30 days where the agent proposes but a human applies, then supervised write access, and finally autonomous operation once the agent sustains consistent accuracy against your SLOs.
Our experiment is a proxy for what shadow mode catches. At the medium tier, where Jaccard dropped to 0.409, shadow mode would have flagged more than half the predicted change set as incorrect. The specific SLO threshold is yours to define; what matters is that it is explicit, measured, and tied to your error budget rather than a gut feeling.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: ai-agent-readonly
rules:
- apiGroups: [""]
resources: [pods, services, configmaps]
verbs: [get, list, watch]
- apiGroups: [apps]
resources: [deployments, replicasets]
verbs: [get, list, watch]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: ai-agent-scoped-write
rules:
- apiGroups: [""]
resources: [pods, services, configmaps]
verbs: [get, list, watch]
- apiGroups: [apps]
resources: [deployments]
verbs: [get, list, watch, update, patch]
resourceNames: [canary-payments]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: ai-agent-production-write
rules:
- apiGroups: [""]
resources: [pods, services, configmaps]
verbs: [get, list, watch, create, update, patch, delete]
- apiGroups: [apps]
resources: [deployments, replicasets]
verbs: [get, list, watch, create, update, patch, delete]sre/trust-ladder-rbac.yamlCode Snippet 2: Kubernetes RBAC ClusterRoles for each trust ladder tier. Promotion from readonly to scoped-write to production-write is a ServiceAccount rebinding; demotion reverses it.
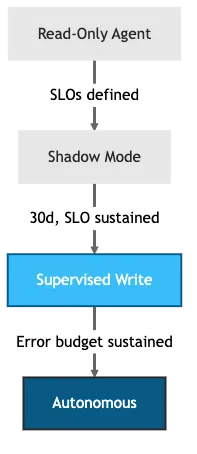
Figure 2: Trust ladder for agentic AI: read-only, shadow mode, supervised write, autonomous.
Accuracy alone cannot distinguish an agent that fails on a fixed subset of tasks from one that fails unpredictably at the same rate (Rabanser et al., 2026). Our 90 runs confirmed consistency (27 of 30 PRs showed zero variance across runs, 3 showed near-zero) but exposed robustness and safety gaps on complex refactoring tasks. Consistent failures are exactly what shadow mode is designed to catch: the model’s errors are systematic, not random, and a human reviewer can filter them. Early evidence supports this approach: STRATUS, a multi-agent SRE system operating under similar progressive constraints, achieved a 1.5x improvement over baselines in automated failure mitigation (Chen et al., 2025).
Why Does Platform Maturity Gate AI Readiness?
The 2025 DORA report is explicit: AI’s impact depends on the quality of the underlying organizational system. Bolt AI onto a fragile platform and you get faster fragility. An AI agent that auto-scales a misconfigured service does not fix the misconfiguration; it scales the blast radius. The AIOpsLab framework shows agent performance varies significantly with the quality of instrumented infrastructure underneath (Chen et al., 2025).
The maturity sequence matters. Build the IDP (internal developer platform) first, layer SRE practices including LLMOps telemetry for token consumption, latency, and decision traces on top, then introduce agentic AI. Skip a step and the agents inherit your tech debt at machine speed.
The Learning Time Deficit
Only 6% of SREs have dedicated, protected learning time (Catchpoint, 2026). You cannot build an SRE practice when the people staffing it have no time to learn the discipline. Concretely, 10% protected time means one half-day per week where an SRE studies agent failure modes, reviews postmortems from other teams, or shadow-tests a new observability tool without on-call interruptions. The organizations with the lowest toil trends treat learning hours like error budgets: protected, measured, and non-negotiable.
| Maturity Level | Platform State | SRE State | AI Readiness |
|---|---|---|---|
| Foundation | Manual provisioning | Reactive ops, no SLOs | Not ready |
| Standardized | Self-service IDP | SLOs defined, error budgets | Read-only agents |
| Measured | Golden paths adopted | Toil tracked, burn-rate alerts | Shadow mode agents |
| Optimized | Platform-as-product | Blameless culture, SLO-driven | Supervised write agents |
| Autonomous | Full self-service | Proactive reliability | Agentic AI with guardrails |
Table 3: Platform + SRE maturity levels and what each unlocks.
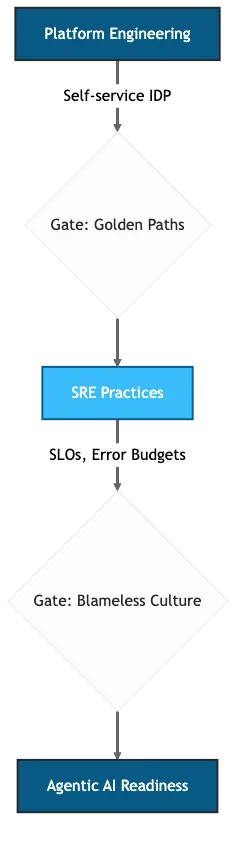
Figure 3: Maturity sequence, platform engineering and SRE prerequisites gate each AI readiness level.
Read-only agents need SLOs because without a defined “good,” the agent cannot distinguish signal from noise. Supervised write agents need blameless culture because humans must feel safe overriding the machine.
Where Should You Start?
Enforce the prerequisites before enabling agentic AI on any service:
package sre.ai.readiness
import rego.v1
default allow_agentic_ai := false
allow_agentic_ai if {
input.slo_defined
input.error_budget_policy
input.shadow_period_days >= 30
input.decision_provenance
input.rollback_automated
input.toil_measured
}sre-readiness-check.regoCode Snippet 3: OPA policy gate enforcing the minimum bar before any service receives agentic AI write access. Shadow period and decision provenance are the two gates most commonly skipped in practice.
The Four Actions in Order
Four actions, in order:
- Audit your toil budget. Measure actual toil against perceived toil. If practitioners report higher friction while dashboards show fewer tickets, you have shifted toil rather than eliminated it. That distinction determines whether your AI investment compounds value or accelerates the same failure modes at higher velocity.
- Define SRE boundaries. One team owns the IDP. Another owns the error budgets. Overlap is where accountability dies. Ambiguity here is the single most common reason SRE functions fail to scale in regulated enterprises.
- Split error budgets by author type. Human-authored and AI-authored deployments have different failure profiles. Track them independently and revoke AI write access when the budget burns too fast.
- Protect learning time. Budget 10% of engineering hours for skill development or accept compounding operational risk. At 6% of teams with protected learning time, the industry is not doing this, and the toil trend reflects it.
Start with the toil audit, the only prerequisite you can measure without instrumentation already in place. Measure first. Then automate.
References
- Becker et al., “Evidence on the Impact of Generative AI on Software Development” (2025) — https://arxiv.org/abs/2507.09089
- Catchpoint, “SRE Report 2026” (2026) — https://www.catchpoint.com/learn/sre-report-2026
- Chen et al., “AIOpsLab: A Holistic Framework to Evaluate AI Agents for Enabling Autonomous Clouds” (2025) — https://arxiv.org/abs/2501.06706
- Chen et al., “STRATUS: A Multi-agent System for Autonomous Reliability Engineering of Modern Clouds” (2025) — https://arxiv.org/abs/2506.02009
- Clouatre, H., “SRE Shadow Replay: File-Prediction Experiment Data” (2026) — https://github.com/clouatre-labs/sre-shadow-replay
- DevOps.com, “Survey: AI Tools are Increasing Amount of Bad Code Needing to be Fixed” (2025) — https://devops.com/survey-ai-tools-are-increasing-amount-of-bad-code-needing-to-be-fixed-2/
- DORA (Google Cloud’s DevOps Research and Assessment), “2025 State of AI-assisted Software Development” (2025) — https://dora.dev/research/2025/dora-report/
- European Parliament and Council, “Digital Operational Resilience Act (DORA)” (2022) — https://www.digital-operational-resilience-act.com/
- Google, “Site Reliability Engineering” (2016) — https://sre.google/sre-book/table-of-contents/
- Jimenez, C. E. et al., “SWE-bench: Can Language Models Resolve Real-World GitHub Issues?” (ICLR 2024) — https://arxiv.org/abs/2310.06770
- OSFI, “Technology and Cyber Risk Management Guideline B-13” (2022) — https://www.osfi-bsif.gc.ca/en/guidance/guidance-library/technology-cyber-risk-management
- Pan et al., “Measuring Agents in Production” (2026) — https://arxiv.org/abs/2512.04123
- Rabanser et al., “Towards a Science of AI Agent Reliability” (2026) — https://arxiv.org/abs/2602.16666