A Google Research paper demonstrates that repeating the entire user prompt verbatim can lift accuracy by up to 76 percentage points at zero output cost. No chain-of-thought overhead. No reasoning budget. Just send the same instruction twice.
We ran 20 parallel agents across two experiments: 10 per experiment, 5 control vs. 5 treatment, blind-scored against a pre-registered rubric.
We found nothing. The nothing is the finding.
Table of contents
Contents
- What Did the Paper Claim?
- How Did We Design the Test?
- What Happened in the FastMCP Refactor Test?
- Did a Stricter Methodology Change the Result?
- What Infrastructure Confound Did We Miss?
- Why Did Both Experiments Hit 100%?
- What Did We Learn About AI Evaluation Design?
- When Should You Use Prompt Repetition?
- Did Prompt Repetition Change Anything Else?
- References
What Did the Paper Claim?
A 2025 paper by Leviathan et al. at Google Research proposes a simple technique: repeat the entire user prompt once, verbatim, before sending to the model.
The mechanism is structural, not empirical. Decoder-only transformers use causal masking: each token attends only to tokens before it. In a single-pass prompt, early tokens never see later context. Repeating the prompt creates a second copy where every token attends to the full instruction during prefill. This reduces the positional attention decay documented as the “lost in the middle” phenomenon (Liu et al., 2023). This is a fundamental limitation of the decoder-only architecture, not a quirk of specific benchmarks. Among decoder-only models, a 675B-parameter Mixture-of-Experts frontier model and a 3B-active-parameter small language model (SLM) (NVIDIA, 2025) share it equally. Bidirectional architectures, including diffusion language models such as Inception Mercury 2, attend to the full sequence in a single pass and do not exhibit this limitation.
Standard prompt (single pass):
Token 1 sees: [Token 1]
Token 5 sees: [Token 1, 2, 3, 4, 5]
Token 50 sees: [Token 1, 2, ..., 50]
--> Early tokens are blind to later context
Repeated prompt (two copies):
Token 51 sees: [Token 1, 2, ..., 50, 51]
Token 55 sees: [Token 1, 2, ..., 50, 51, 52, 53, 54, 55]
--> Every token in the second copy attends to the full first copy
--> Full context available during prefill, zero generation costcausal-masking.txtCode Snippet 1: Causal masking creates an asymmetry where early tokens cannot attend to later context. Repeating the prompt gives the second copy full visibility over the first.
The reported gains:
- Gemini 2.0 Flash-Lite on NameIndex: 21.33% to 97.33% accuracy
- GSM8K and MMLU-Pro gains across Gemini 2.0 Flash, GPT-4o, Claude 3.7 Sonnet, DeepSeek V3, and others
- Input tokens double; output tokens unchanged in fixed-format benchmarks (no latency increase, unlike chain-of-thought)
The paper positions this as a Pareto improvement over reasoning-heavy approaches: same output budget, better accuracy.
Why Our Agent Seemed Like a Good Candidate
Our Scout delegate, the research agent in our subagent architecture (full recipe), runs on claude-haiku-4-5 at temperature 0.5 with extended thinking off. Haiku 4.5 is structurally a non-reasoning model (extended thinking is opt-in, not default), making it precisely the class of LLM the paper’s title targets.
The paper tested Claude 3 Haiku alongside six other models; its strongest gains came from Gemini 2.0 Flash-Lite and GPT-4o-mini. We tested Claude 4.5 Haiku, a different model generation. Anthropic does not publish architectural details for either model. Whether the technique transfers across generations is an open question this experiment cannot answer, because our ceiling effects prevented any treatment from showing lift.
Why This Matters for Engineering Teams
Teams adopt AI techniques from papers without field-testing them first. BCG reports that 50% of companies are stagnating with AI (BCG, 2025), partly because they ship optimizations without measuring baselines. Shipping an unvalidated prompt change to production would cost more: doubled input tokens on every request, with no accuracy gain to show for it. As we covered in observability for AI agents, optimizing without measuring before and after is flying blind.
How Did We Design the Test?
Both experiments shared the same core structure: 10 parallel async Scout delegates, split 5 control vs. 5 treatment, scored blind against a pre-registered rubric. For detailed methodology and raw data, see Supplementary Materials.
# Shared config across all 10 delegates
model: claude-haiku-4-5
temperature: 0.5
extensions:
- developer
- context7
- brave_search
output: "scout-run-{{ id }}.json"delegate-config.yamlCode Snippet 2: Shared delegate configuration. All 10 runs use the same model, temperature, and extensions.
Control group: standard Scout instructions (~3,805 characters, instructions x1).
Treatment group: instructions repeated verbatim (~7,633 characters, instructions x2), mimicking the paper’s <QUERY><QUERY> pattern applied to the agent’s system prompt.
The orchestrator spawned all 10 delegates simultaneously via Goose’s background task system and handed off structured JSON. A separate blind-scoring delegate received only the output files (no group labels) and scored each against the rubric. Group assignments were sealed in a label map before scoring began.
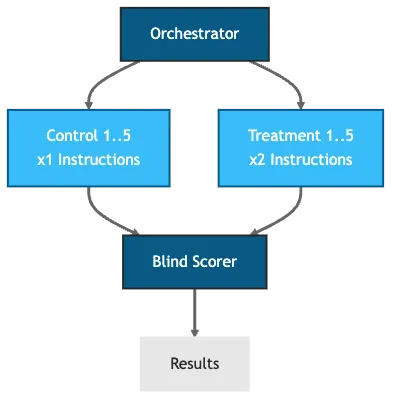
Figure 1: Blind evaluation pipeline. Group labels are stripped before scoring to prevent bias.
What Happened in the FastMCP Refactor Test?
Target: FastMCP session ID refactor in math-mcp-learning-server. Open and unimplemented at the time of the experiment.
Rubric: 6 binary criteria, pre-registered before any runs were examined.
9 of 10 delegates produced valid output. control-1 ran 93 messages and wrote no output file. Session log analysis confirmed the file-write instruction appeared only at the end of the delegate prompt, and the model drifted past it. This is a delegate authoring flaw with a known fix: bookend critical instructions at the start and end.
Across the 9 valid runs, 5 of 6 criteria scored 100% in both groups. The only variance was C5 (must-not constraint violations): control 5.50/6, treatment 5.80/6, delta +0.30. The treatment scored marginally higher, but at n=4 vs n=5 with binary outcomes, Fisher’s exact test is degenerate (p = 1.0). Full per-criterion scores are in the raw data.
The task was too easy. The rubric could not discriminate. We needed a harder target.
Did a Stricter Methodology Change the Result?
Target: aptu#737, a tree-sitter AST (Abstract Syntax Tree)-based security scanner evaluation. Harder task, requiring synthesis from source code rather than retrieval from issue text. Unimplemented when tested.
Rubric: 7 binary criteria. C5, C6, and C7 required the delegate to read and reason about actual source code, not just summarize the issue. Pre-registered before any runs began.
Methodology improvements over Experiment 1:
- Blinded file naming from the start (
scout-run-01.jsonthroughscout-run-10.jsonwith sealedlabel-map.json) - Mann-Whitney U test pre-specified (two-tailed, alpha = 0.05)
- Wall-clock latency recorded per delegate
Results:
| Group | Score | Wall-clock median |
|---|---|---|
| Control (x1) | 7/7 all runs | 6m 21s |
| Treatment (x2) | 7/7 all runs | 7m 29s |
| Delta | 0 | +17.8% |
Table 1: Experiment 2 results. Zero variance in either group. Mann-Whitney U = 12.5, p = 1.0 (degenerate: complete ties, test cannot be evaluated).
Every Scout, in every run, in both groups, scored 7/7. Even C5, C6, and C7, the synthesis criteria we specifically designed to require source code reasoning, hit 100% across the board.
The 17.8% latency difference is in the expected direction (longer prompt, longer prefill), which is consistent with the paper’s Anthropic-specific latency caveat. At scale, that delta compounds: doubled tokens cost money, and the added prefill time costs throughput across every agent invocation. But n=5 cannot support any inference here, and the finding is further confounded by an infrastructure issue we discovered afterward.
The scores told us nothing. The session logs told us something we did not expect.
What Infrastructure Confound Did We Miss?
Post-hoc session log analysis revealed a confound present in both experiments.
Goose enforces a hard cap of 5 concurrent background delegates. When all 10 delegates were spawned simultaneously, runs 06-10 hit the cap and were queued into a second batch after runs 01-05 completed.
The resulting batch structure was unbalanced:
| Batch | Runs | Control | Treatment | Condition |
|---|---|---|---|---|
| 1 (runs 01-05) | 5 | C1, C2, C3 | T1, T2 | Resource contested |
| 2 (runs 06-10) | 5 | C4, C5 | T3, T4, T5 | No contention |
Table 2: The 5-delegate concurrency cap split 10 simultaneous spawns into two unbalanced batches. Exact run assignments are in the raw data.
Treatment delegates landed disproportionately in the less-contested second batch, making any latency comparison between groups uninterpretable. Accuracy was unaffected (ceiling effects dominated regardless), but the exposure is worth naming: pre-registration does not protect against runtime infrastructure behavior you did not know existed.
The confound matters for latency. But the bigger question is why accuracy showed zero variance in the first place.
Why Did Both Experiments Hit 100%?
Two experiments, two rubrics designed to be harder than the last, two 100% results.
This is itself a finding. A well-designed Scout delegate on a well-scoped engineering issue is already operating above the baseline accuracy threshold where prompt repetition shows lift. The paper’s largest gains came from synthetic positional tasks, NameIndex (Leviathan et al., 2025), where the answer is a name buried in a list. Real engineering issues, even unimplemented ones, give the agent structured context, code references, and acceptance criteria. The agent finds what it needs without help from the prefill geometry.
This is the core finding: prompt repetition solves an attention problem that well-scoped engineering tasks do not have. The technique’s value is real, but the paper’s benchmarks do not cover agentic engineering tasks. Our experiments tested that boundary. When the agent already has structured context pointing it to the right code, repeating the instruction adds input tokens without adding accuracy signal. Understanding where SLMs succeed and fail on their own is not academic: hybrid architectures like SMART (Kim et al., 2025) use SLMs as the primary reasoning engine, with LLMs intervening only at critical junctures. Every prompt-level optimization that improves standalone SLM accuracy reduces how often the expensive backstop fires.
For teams evaluating prompt techniques at scale, the implication is financial: doubling input tokens across every agent invocation is a measurable cost increase. If your agents already converge correctly on well-scoped tasks, that spend returns nothing. Embracing negative results as a research practice (Berger et al., 2024) prevents exactly this kind of waste: publication bias toward positive results means the null findings that would have saved you the experiment often go unpublished.
Where the Boundary Falls
The gap is between task types, not between models:
- Positional retrieval tasks (NameIndex, needle-in-haystack): high positional attention decay, repetition helps
- Structured engineering tasks (scoped issues with code context): low positional decay, Scout already converges correctly
| Dimension | Paper (Leviathan et al.) | Experiment 1 | Experiment 2 |
|---|---|---|---|
| Task type | Standard + custom retrieval (MMLU-Pro, NameIndex, others) | Issue analysis (FastMCP refactor) | Source code synthesis (AST scanner) |
| Model | Gemini 2.0 Flash-Lite, Claude 3 Haiku, 5 others | Claude 4.5 Haiku | Claude 4.5 Haiku |
| Sample size | McNemar test on full benchmark datasets (7 benchmarks, 7 models) | n=4 vs n=5 (1 dropped) | n=5 vs n=5 |
| Accuracy delta | 47/70 pairs improved, 0 regressed; +76pp on NameIndex (Flash-Lite) | +0.30 (noise) | 0.00 (ceiling) |
| Confounds | None reported | Delegate authoring failure | 5-delegate batch cap |
Table 3: Comparison of experimental conditions. The paper’s gains concentrate on positional retrieval tasks; our structured engineering tasks hit ceiling effects before any treatment could show lift.
Designing a rubric that discriminates between good and very good on the second category is harder than it looks. Both of ours failed. The criteria require synthesis and judgment under genuine ambiguity, not retrieval from a well-scoped document.
What Did We Learn About AI Evaluation Design?
Rubric Design Is Harder Than Experiment Design
We iterated twice and hit the ceiling both times. A 7-point rubric with “source code synthesis” criteria is not automatically harder. It depends on whether the task actually creates ambiguity the agent must resolve. Ours did not.
A practical calibration target: if your scoring delegate can answer any criterion by reading the issue alone (without running the code), the criterion will not discriminate.
Infrastructure Behavior Is a Confounder
The 5-delegate cap is undocumented. It is enforced as a hard rejection in source (GOOSE_MAX_BACKGROUND_TASKS defaults to 5), with no queuing or retry. Excess delegates are dropped, not deferred. It silently split our groups into unbalanced batches. This category of confound (runtime resource limits, queue behavior, model routing) is endemic to agent systems and invisible without structured logging.
Future experiments: spawn delegates in explicit batches of 5 with documented batch assignments. Record session IDs. Treat infrastructure state as a variable, not background noise.
Delegate Authoring Has a Turn-Length Problem
Long sessions drift from instructions that appear only once. The control-1 failure (93 messages, no output) demonstrated the fix: bookend critical actions at both the start and end of delegate prompts. This class of failure is predictable and preventable, but only if you treat delegate prompt structure as part of your experimental design.
The blind scoring infrastructure proved its value here. Each run produced a structured justification the scorer generated without knowing group assignment:
{
"run_id": "run-01",
"C1": 1, "C2": 1, "C3": 1, "C4": 1,
"C5": 1, "C6": 1, "C7": 1, "total": 7,
"justifications": {
"C1": "Issues #735/#736 explicitly identified as regex limitation.",
"C5": "Backward compatibility addressed via hybrid approach.",
"C7": "Synthesis connects tree-sitter AST parsing to existing rules."
}
}scorer-output.jsonCode Snippet 3: Blind scorer output for a single run. Each criterion includes a justification generated without knowledge of group assignment.
When Should You Use Prompt Repetition?
The null result is not a failure of the paper. Prompt repetition won 47 out of 70 benchmark-model combinations with zero losses (Leviathan et al., 2025). The technique works. The question is where.
The paper’s gains concentrate on benchmarks with positional retrieval components: NameIndex, MiddleMatch, options-first multiple choice. Tasks where the answer depends on information placement in the context window. The paper also notes a neutral-to-slight effect with reasoning prompts (5 wins, 1 loss, 22 neutral with step-by-step). Reasoning appears to compensate for the same attention decay that repetition addresses.
The industry trend is not exclusively toward reasoning models. Capable SLMs are gaining ground. NVIDIA’s Nemotron 3 Nano (NVIDIA, 2025) activates 3 billion of its 30 billion parameters per token, delivering 3.3x the throughput of Qwen3-30B on a single H200, designed explicitly for multi-agent systems at scale. RLP (Hatamizadeh et al., 2025) embeds reinforcement learning into pretraining itself, lifting math and science accuracy by 19% on a 1.7B-parameter model without post-training reasoning. These models are non-reasoning by default. The causal masking limitation that prompt repetition addresses is structural to the decoder-only architecture all of them share. Their users are also the most cost-sensitive to doubled input tokens. Every token matters when you are optimizing for throughput at the edge.
Our null result came from the other side of that boundary: structured engineering tasks where the agent already has scoped context, code references, and acceptance criteria. The ceiling was in the task, not the technique.
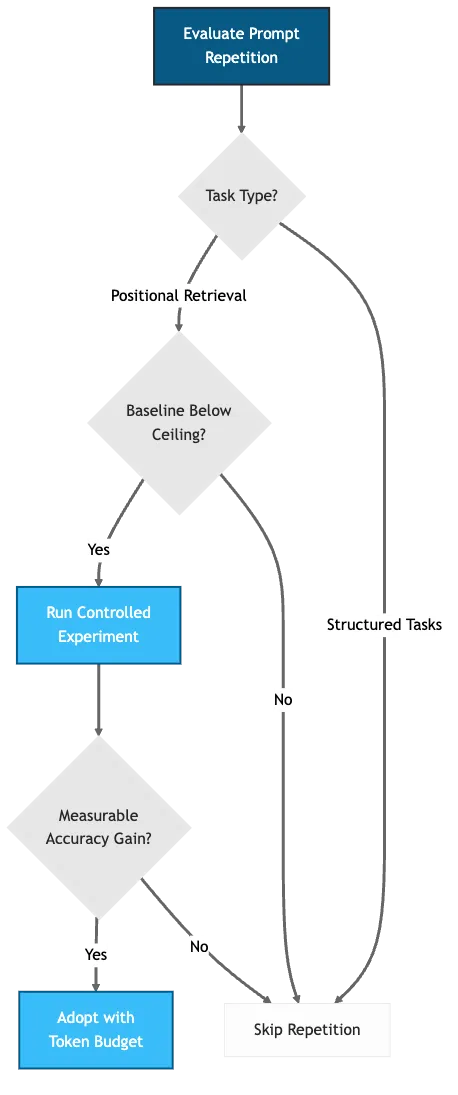
Figure 2: When to use prompt repetition. Three decision points, two outcomes.
What Transfers to Your Team
Three things that transfer directly to any team evaluating AI agent behavior:
- Baseline accuracy determines whether any prompt technique has room to work. Measure it before testing an optimization.
- Infrastructure constraints are confounder candidates. Audit your delegate system’s limits before attributing latency or throughput differences to treatment variables.
- Rubric discrimination is the bottleneck. Two rubrics, two ceiling effects. If your scoring criteria can be satisfied by reading the issue description alone, the rubric will not discriminate.
Did Prompt Repetition Change Anything Else?
One observation worth noting: treatment agents in both experiments used fewer output tokens and messages to reach the same scores. This is consistent with what the attention mechanism would predict; a richer prefill context may reduce exploratory turns in an agentic loop, though the mechanism is not established. The original paper’s benchmarks (MMLU, GSM8K) produce fixed-format answers where output length does not vary, making this effect invisible. Agentic workloads, where the model decides how many turns to take, may be where the efficiency signal surfaces.
The economics are also different than single-turn benchmarks suggest: in a multi-turn session, the doubled prompt adds single-digit overhead to accumulated input, not 100%. The growing conversation history dominates each API call. In our data, treatment agents used 13.1% fewer input tokens and 15.4% fewer output tokens despite the longer prompt. Each avoided turn eliminates an entire context window from the running total. The effect is confounded and too small to draw conclusions, but it is a pattern worth investigating with a discriminating rubric.
For how file-prediction accuracy maps to production governance, see SRE for AI Agents: Error Budgets, Trust, and 90 Trials.
References
- BCG, “AI Adoption Puzzle: Why Usage Is Up But Impact Is Not” (2025) — https://www.bcg.com/publications/2025/ai-adoption-puzzle-why-usage-up-impact-not
- Berger et al., “Position: Embracing Negative Results in Machine Learning” (2024) — https://arxiv.org/abs/2406.03980
- Clouatre, H., “Orchestrating AI Agents: A Subagent Architecture for Code” (2025) — https://clouatre.ca/posts/orchestrating-ai-agents-subagent-architecture/
- Clouatre, H., “Prompt Repetition Experiments: Supplementary Materials” (2026) — https://github.com/clouatre-labs/prompt-repetition-experiments
- Hatamizadeh, A. et al., “RLP: Reinforcement as a Pretraining Objective” (2025) — https://arxiv.org/abs/2510.01265
- Kim, Y. et al., “Guiding Reasoning in Small Language Models with LLM Assistance” (2025) — https://arxiv.org/abs/2504.09923
- Leviathan, Y., Kalman, M., and Matias, Y., “Prompt Repetition Improves Non-Reasoning LLMs” (2025) — https://arxiv.org/abs/2512.14982
- Liu et al., “Lost in the Middle: How Language Models Use Long Contexts” (2023) — https://arxiv.org/abs/2307.03172
- NVIDIA, “Nemotron 3: Efficient and Open Intelligence” (2025) — https://arxiv.org/abs/2512.20856